My wife is a huge fan of the podcast Armchair Expert with Dax Shepard. She listens every week and is constantly learning about new books, movies, documentaries and other types of media from the conversations the shows hosts, Dax and Monica, have with their wide variety of guests. Throughout each show the guests and hosts talk about so many bits of media, it was hard for my wife to keep track of it all. Especially if she was driving or doing something that wouldn't allow her to write down a cool new podcast they were talking about. This gave her an idea - what if we create a dictionary of all the different media that is talked about in the Armchair Expert podcast? Over the last four months we have been building the Armchair Media Explorer - a website that keeps track of every book, show, movie, documentary, article and podcast that's mentioned in each show.
This is a blog post about the technology and basic functionality of the website. I decided to use a "boring tech" stack to develop the site in order to get it out the door as quickly as possible. It's built on .Net 7 Razor Pages with a MySql back end and styling with Bootstrap CSS. Like I said, it's not a hot new tech stack, but rather a tried and true client/server website. There is not a ton JavaScript that's needed with the current build so jQuery works just fine. I could see it being a good app if I developed it in React, but I didn't want to have to spin up a whole new web project and API project, so I went with a classic .Net build.
Data Collection Process
Overall the website is heavy on CRUD with a little bit of third party API integrations for the the cover work for media on the media list page. All the data elements are gathered manually by someone listening to an episode and taking notes to record all the different media that is mentioned during an episode. After the episode is over and media items noted, a person logs into the back end and enters the media into a media database that contains different media types (books, movies, podcast, etc). This is a simple CRUD interface that allows us to link media to episodes and an episode to a list of media items. There's a C# console app job that runs every morning to hit the Spotify API and get the latest Armchair Expert episode details and the episode image. This saves us time so we don't have to sync up episodes in our database with the official list of episodes in Spotify.
In the beginning every piece of media and episode was entered into a Google Sheet with the name of the episode with a column per media item and separated the media by a comma. The spreadsheet was then imported via a custom C# console app. We eventually phased out the data loader for custom admin CRUD pages in the back end.
When one of the admins logs in to the website they select the episode they want to add media to - thanks to the Spotify API - then they can enter the media along with a link to the source. This media gets rendered as a link on the home page if a URL is provided to the media item.
Home Page
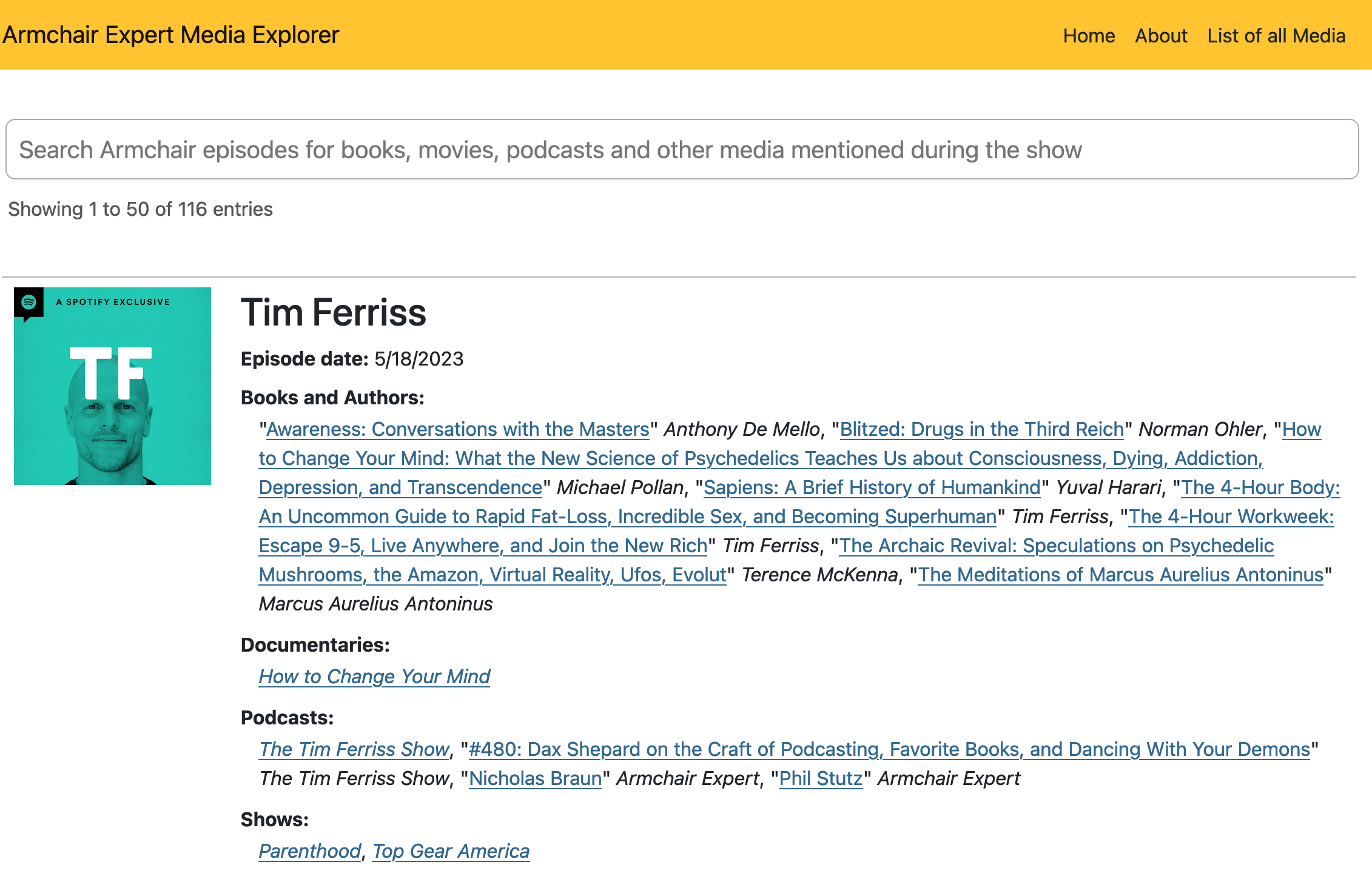
The home page is rendered using DataTables with some custom HTML configurations to enable the search across the entire episode card. From the main search box you're able to search any of the text that resides within the episode card. That could be the title of the episode as well as every media item displayed on the screen. This is a great two way reference for you to search an episode. The first way is if you are looking for a book that was mentioned during an episode but can't quite remember the name of the book. You can look up the episode name and browse the books mentioned. The second is if you wanted to go back to look up an episode that mentioned a movie you remember the name of, but can't remember which guest talked about the movie. By finding the movie name you'll see every episode that movie was mentioned in. In the end, it's all rendered inside a single table cell which allows the DataTables code to do a real full-text search on every piece of content that is being tracked.
The display for each of the media types is slightly different between them all. In the C# code behind there is a set of business rules that determine the rendered style of each media item.
Media Page
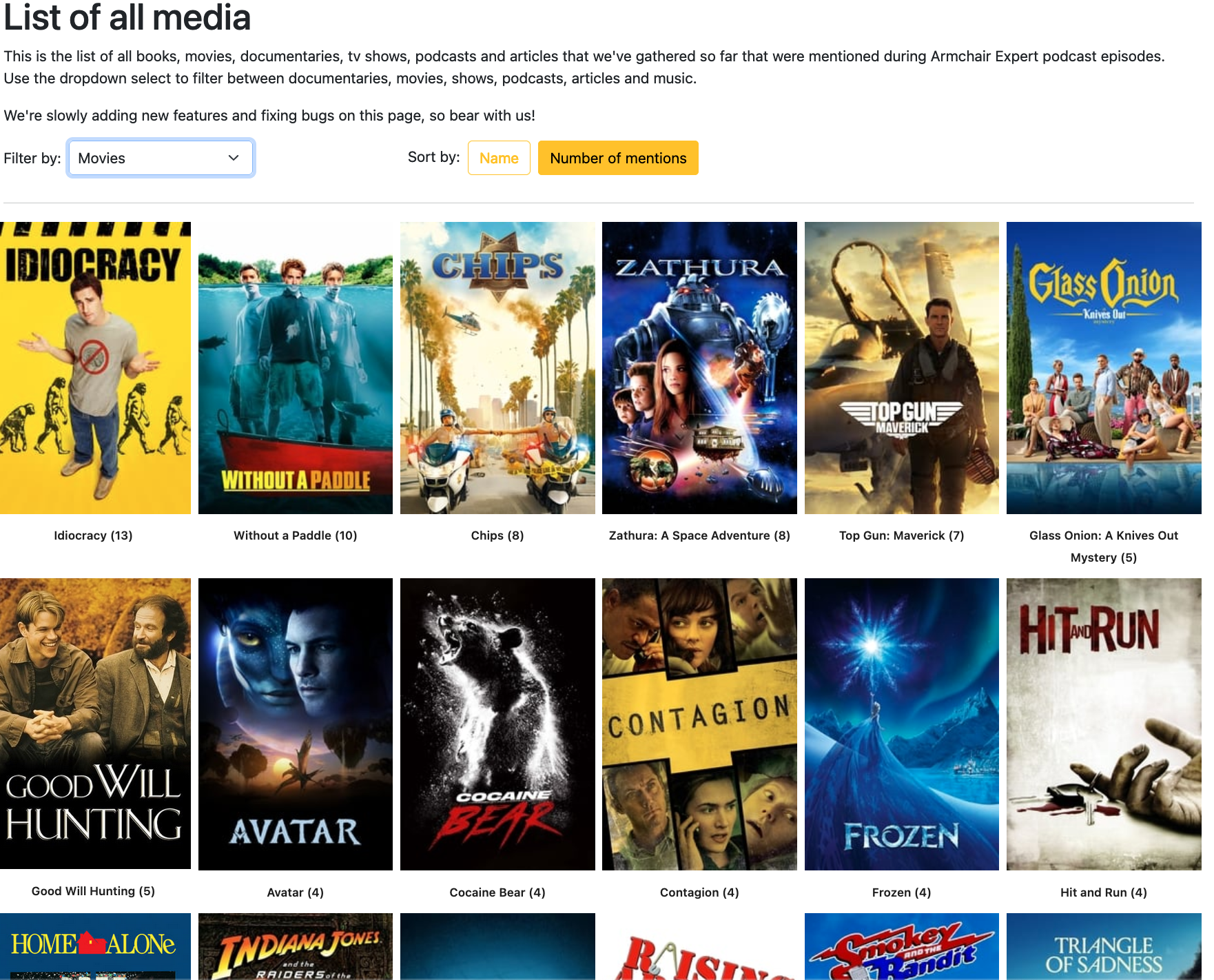
This is the part of the application that gets exciting. We've created a page on the website that displays all the media mentioned during the podcast broken down by type. The list displays the movie poster/cover art/book cover/etc to give a nice visual. Just like you are searching Netflix or Hulu. Just flipping the drop down you're able to switch between media types. There is also two buttons, one to sort alphabetically and another to sort by most mentioned. The website defaults to most mentioned media during all tracked episodes.
In addition to the artwork for each media type, there's the number the individual media item has been mentioned in the show. This is a fun piece of data analytics we are tracking so after an amount of time, we can look to see what books are most discussed, what movies are talked about the most or what's the most popular podcast mentioned in the Armchair Expert podcast. The future phases of the app will include data visualizations to make the data more interesting to look at. We need a little more data before we can implement this functionality.
As you can see, for each media type there is a list of the media mentioned on the show and whatever the cover art may be. If the media type is a movie, documentary or show we display the poster from The Movie Database, for book/author types the book image is displayed from Open Library and podcasts and music are displayed from the Spotify API. I'm still working on a integration for the article and misc. types. But for each of the media types that we're able to get cover art for, there is a specific API available that we are able to call. This enables us to not have to save each individual cover art as all the images are saved on the various services servers allowing us to save on storage space. I'll write another blog post on how we are actually calling and implementing each of those end points another time.
I can see the media page being extremely valuable for users who want to see what the most popular shows or movies are. For example, there is a A LOT of content to watch on all the streaming services. Sometimes, I just want to watch a documentary but I'm always overwhelmed by my choices. Now I can go to the media list page and see what the most popular documentaries are being talked about on the Armchair Expert podcast and go from there. In a way this little website we've created is a recommendation engine for our media.